RSSに対応していないページの更新確認を行う作業を面倒に感じませんか?
RC2 にバージョンアップした Headline-Reader Plugin の HTML 抽出機能を利用すれば、それらの作業が簡単に行えます。
HTML抽出機能とは
ページに新たに追加された文字列リンクを抽出することにより、RSSに対応していないページの新着情報を知る機能です。
たとえばニュースサイトの新着情報一覧や、mixi の等のソーシャルネットワーキングサイトの新着情報一覧等を取得することが可能になります。※ログインが必要なページであっても、ログイン状態を保持することが可能なサイトであれば、HTML 抽出機能が利用できることを確認しています。
登録方法
フィード/OPMLの追加ダイアログ上で、URLを入力し、HTML抽出機能にチェックをいれるだけで登録可能です。
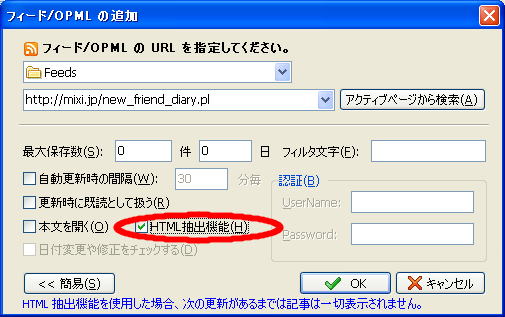
フィルタ文字
リンクのタイトルに含まれる文字列との比較によりフィルタ処理をおこなうことができます。一定の法則で追加されるリンクのタイトルをフィルタすることが可能です。
* ワイルドカード
! 除外
スペースで区切ることにより複数ワードの指定が可能です。
また、単一のキーワードの中にスペースが含まれる場合は「”」で囲みます。
(例)
!関連記事*件
関連記事1件、関連記事2件 のような、動的なリンクをフィルタリング可能です。
除外するURL
抽出したいページに、ページを取得する毎にURLが変化してしまうリンクが存在する場合があります。この場合は除外するURLを指定しておけば、それらのリンクが自動で抽出対象から削除されます。
Headline Panelのオプションボタン|設定|Headline拡張機能、および ツール|Sleipnirオプション|Headline拡張機能より指定することが可能です。
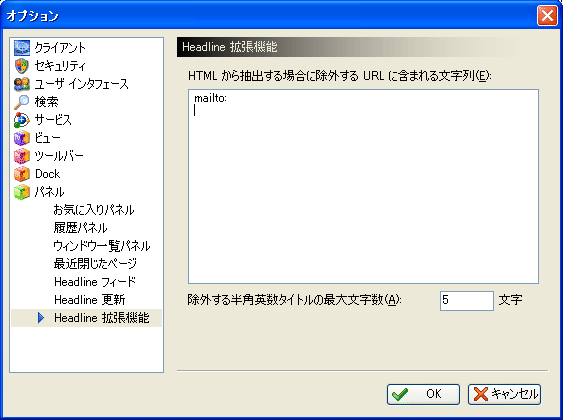
http://test.fenrir.co.jp/…
上記の … の部分がページ取得毎に規則的に変化する場合、http://test.fenrir.co.jp/ を指定除外の対象にしておく事で、抽出対象外となります。
これらの機能を利用して、より効率よく情報収集を行ってください。
※Headline-Reader Plugin の動作には Sleipnir 2.40 beta1 が必要です。
Headline-Reader Plugin RC2 のダウンロード : Fenrir Extensions Center
Headline-Reader Plugin への要望・質問はこちら : Fenrir User Community
※尚、抽出結果は必ずしも意図する結果にならない可能性がありますので、ご了承願います。
関連記事









